
Introduction
既存の手法では、一部のCleanなラベル、ノイズについての事前情報が必要であった。
この論文では、以下のような貢献をしている。
- PENCILというend-to-endのフレームワークを提案した。ネットワーク本体の構造とは関係ないもので、本来のパラメタを更新する前に確率的にサンプルのラベルを修正するものである。
- PENCILはロバストであり、Noisy Labelに強いだけではなく、ノイズがないと思われる環境でも存在する潜在的なノイズに対しても強いとわかった
- この論文のやっていること
- ラベルは固定された値ではなく、分布で表すように考える。
- 先行研究を参考し、ラベルの分布をネットワークの学習の時とラベルのノイズ除去?の時と同時に各イテレーションごとに行う。
Related Work
Deep Label Distribution Learning。分布を離散化してKLダイバージェンスの最小化をするという手法らしい。
Bin-Bin Gao, Chao Xing, Chen-Wei Xie, Jianxin Wu, and Xin Geng. Deep label distribution learning with label ambiguity. IEEE Trans. Image Processing, 26(6):2825–2838, 2017.
DNNの記憶力が高くてNoiseまで覚えてしまうことを言ってるらしい。
Zhilu Zhang and Mert R. Sabuncu. Generalized cross entropy loss for training deep neural networks with noisy labels. In NIPS, 2018
学習率が高ければ、高いAccuracyを保てるらしい。移動平均をとるという手法。PENCILはその改良版
Arash Vahdat. Toward robustness against label noise in training deep discriminative neural networks. In NIPS, pages 5601–5610, 2017.
Tong Xiao, Tian Xia, Yi Yang, Chang Huang, and Xiaogang Wang. Learning from massive noisy labeled data for image classification. In CVPR, pages 2691–2699, 2015.
Jiangchao Yao, Jiajie Wang, Ivor W Tsang, Ya Zhang, Jun Sun, Chengqi Zhang, and Rui Zhang. Deep learning from noisy image labels with quality embedding. IEEE Transactions on Image Processing, 2018.
提案手法のPENCIL
文字表記
- ハードラベルはone-hotなラベルであり、がその空間だとする。
- ソフトラベルはone-hotではなく実数をとるが、和が1である。その空間はである。
- これがラベル分布であるとみなせる。
- よく見たらlabel smoothingっぽいよな。
Noisy Labelの確率モデル
このPENCILという手法では、に所属するone-hotラベルではなく、に属するソフトラベルを使用する。そしてそのソフトラベルを学習を通して徐々に変化させていく=修正していく。
既存のDLDLでは、以下のものを損失として使っていた。
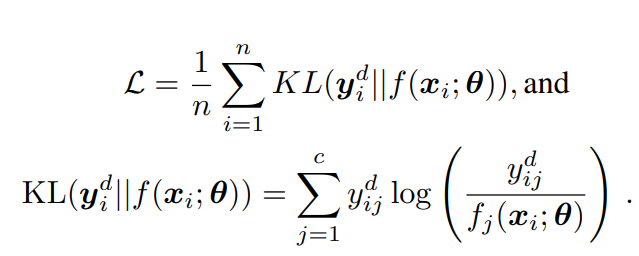
だが、KLダイバージェンスの中身を入れ替えたほうがよりうまく表現できる。
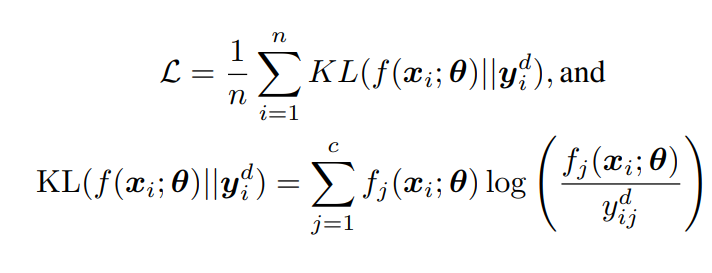
なぜなら、ラベル分布(後述)について更新したいため、を計算したい。それぞれの微分は上下のKLダイバージェンスに対応している。
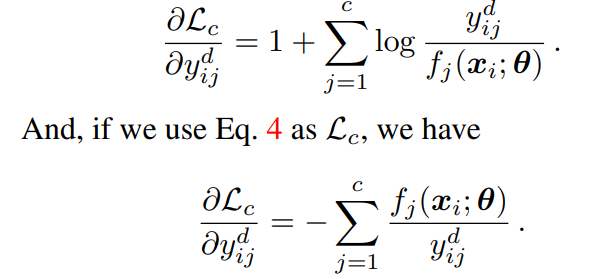
この時、下のほうが極端にのgradientが変わる。PENCILで提案した分布の極端な遷移は、極端なgradientで動かすほうが有効だそうだ。
全体的な構造
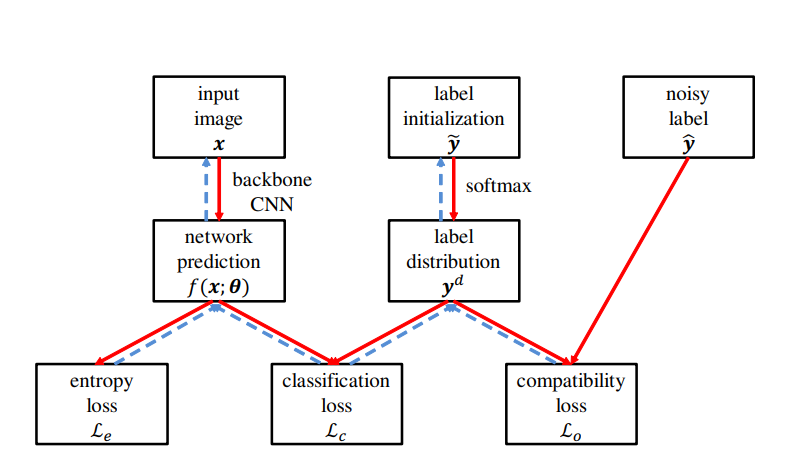
赤線が順伝搬、青点線が逆伝搬。
- ラベルは3種類ある。
- は与えらえれたNoisyなone-hotラベル。
- ははじめはで更新される。はハイパラで、実験では10としてる。
- つまり最初はone-hotのまま。
- がをsoftmaxしたもの。
- 最初では、からsoftmaxされるので、ある程度突出しながらもsmoothingなが得られる。
- 損失は3種類ある。
- Compatibility Loss 与えられたラベルはNoisyと言っても大半が正解なので、大きくはから離れてほしくない。よって、以下のようなとによる全について合算したクロスエントロピー誤差をつけ、大きく離れないようにした。
- Classification Loss 上で議論したKLダイバージェンスの部分そのもの。予測結果と分布の距離を測る。と表記しているが、これはである。
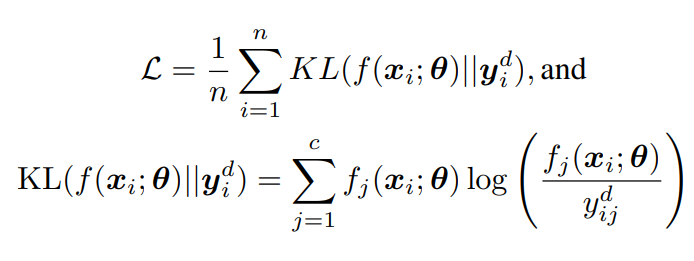
- Entropy Loss はを目標に学習するが、同じような分布になったら更新が止まる。経験上これは早期に止まりすぎているので、止まるならせめて1つのピーク値を作って止まるように、正則化項としてエントロピー項で正則化を加える。
- Compatibility Loss 与えられたラベルはNoisyと言っても大半が正解なので、大きくはから離れてほしくない。よって、以下のようなとによる全について合算したクロスエントロピー誤差をつけ、大きく離れないようにした。
全体的な損失関数
カテゴリ数であるとき、がハイパーパラメタとすると以下のように損失関数を組み立てる。
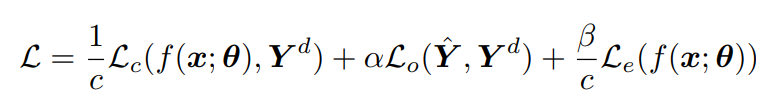
なお、Backbornのモデルが完璧に訓練されていたら、PENCILのフレームワークはいらない。
実際の訓練では、記憶の順序などを考慮し以下のように行う。人力でカリキュラム学習みたい。
- 高い学習率で学習すればNoiseに過学習しづらいので、まず高い学習率でBackbornを訓練する。目標はある程度正しいものを導入。
- PENCILフレームワークを導入して、分布を学習させる。学習率はまだ高いままにしておく。なお、PENCILのの更新はKLダイバージェンスのところでもふれたが、さらに高い学習率をもっと高くしておく=そうしないとNoisyがピークの分布から正しいものがピークの分布に収束しない。
- にして、だけで学習する。もうすでに十分には正しい分布になったからである。
Experiment
使うデータセットは以下の通り。
- CIFAR-100 10%をvalidationにして、人工的に対称的、非対称的ノイズを付与。
- CIFAR-10 上と同様
- Clothing1M もともとNoisyなデータセット。40%間違えているという。非対称ノイズが多い。データ分布が著しく一様ではないので、一様なものを人工的に選び出して実験した。
- CUB-200 NoisyではないデータセットのはずなのにPENCIL使ったら性能上がったので実はNoisyだったんじゃないの?
Noise率が高いとPENCILの利点が出るがさすがに高すぎる=80%とかになるとbootstrappingするのに向いてないよ。